Nate: How It Was Presented vs. How It Was Built
In April 2025, the DOJ and SEC charged Nate founder Albert Saniger with securities fraud and wire fraud for telling investors the app was powered by AI when it was actually powered by humans in a Philippine call center. The press coverage treats this as a simple story — CEO allegedly lied, company collapsed, fraud charges filed. But I worked on the automation system at Nate, and the real story is more specific and more interesting than the coverage suggests. There was a genuine effort on the part of the team — most (all?) of whom were unaware of the CEO's alleged lies — to make those alleged lies a reality. Explaining how the system actually worked — the architecture, the economics, the engineering choices — provides a more complete picture than the indictment alone.
This is a description of what we built, how it worked, and what the CEO told investors it was.
What we were trying to do
Nate was a shopping app. A user would find a product on any online retailer, share the link to Nate, and Nate would complete the purchase — navigate to the product page, select the right size and color, add it to cart, enter shipping and payment information, and check out. The user tapped one button. Everything else happened behind the scenes.
The technical challenge is obvious: there are tens of thousands of online retailers, each with a different website structure, different checkout flow, different form fields, different anti-bot protections. There is no universal API for "buy this thing on the internet." Every retailer is a bespoke problem.
When I joined in 2020, the automation rate — the proportion of orders completed without human intervention — was zero. Every single order was completed by a human worker. My job was to help change that.
The architecture
We looked at our merchant distribution by traffic and found what you'd expect: it followed a power law. The top 10 merchants constituted roughly 50% of all order volume. The distribution was highly skewed — a small number of merchants generated most of the traffic, and a very long tail of merchants generated the rest.
This shaped the entire automation strategy. You don't build one system to handle all merchants. You build specialized systems for the merchants that matter most, and you let a general-purpose fallback handle the rest. Each automation method has different economics — a different average cost per order and a different throughput ceiling — so you assign merchants to methods based on where you get the best return.
The system worked like a router. An order came in. We extracted the base URL of the merchant. If we had an automation method mapped to that merchant, the order was routed to that method. If we didn't recognize the merchant, or if we had no automation coverage for it, the order went to the manual team. If an automated method attempted to execute the order and failed — the site had changed, the bot got blocked, the checkout flow broke — the order was rerouted to the manual team as a fallback.
Here is a simplified view of the system:
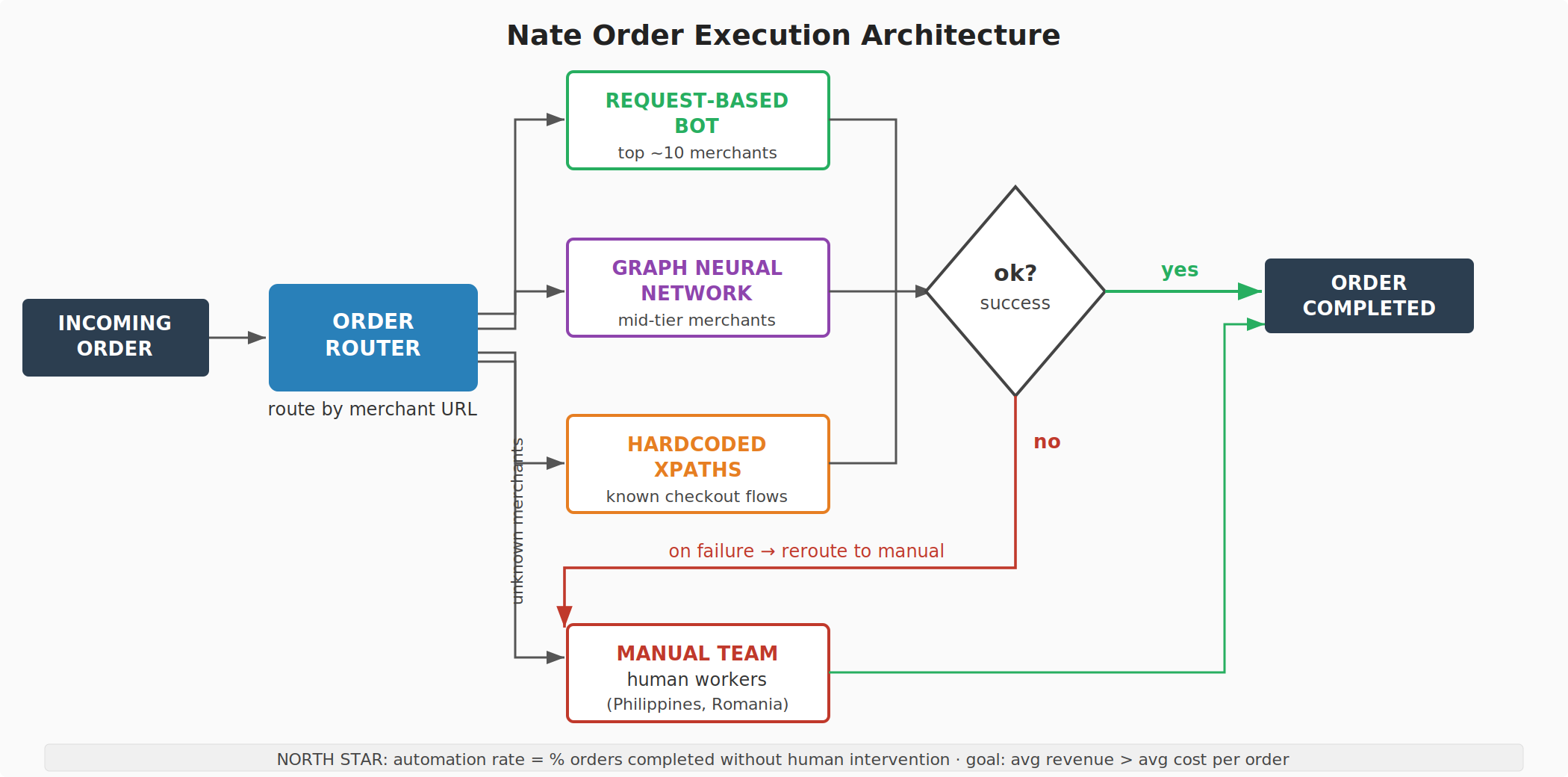
There were four execution methods:
Request-based bots. For the top merchants — the ones generating roughly half of all traffic — we built direct HTTP request automations. This is a technique borrowed directly from the sneaker bot community, and it is not browser-based. The bot never opens a browser. Instead, it sends raw GET and POST requests directly to the retailer's server endpoints — the same endpoints that fire when a real user clicks "add to cart" or "place order" and the page reloads.
The hard part is anti-bot detection. Retailers deploy systems like Akamai Bot Manager, PerimeterX (now HUMAN), and Cloudflare that inject JavaScript on the page to collect "sensor data" — mouse movements, screen resolution, installed fonts, typing cadence, scroll behavior, browser fingerprint attributes — and package it into an encrypted payload. This payload is submitted as a POST request to the anti-bot system's validation endpoint, which checks whether the data looks like it came from a real human in a real browser. If it passes, you get back a session cookie (e.g., Akamai's _abck cookie) that authenticates subsequent requests as legitimate.
To build this, we hired people from the sneaker bot world. One of them was Iwan Jeffery, who created Splashforce, one of the most well-known sneaker bots on the market. Jeffery is a self-taught British developer who had built Splashforce from a Python script into a commercial product generating $700,000 in annual sales by age 21 — all without formal programming training. Business Insider profiled him in 2020. What sneaker botters do — and what our team did — is reverse-engineer the anti-bot system's obfuscated JavaScript to understand exactly what sensor data it collects and how it encrypts the payload. Then they compose a synthetic payload that contains fabricated but correctly structured sensor data: realistic mouse movement trajectories, plausible screen dimensions, valid browser fingerprint values, properly timed interaction events. The anti-bot system receives this payload and concludes it came from a real human. It didn't. The entire interaction — from first request to completed checkout — happens in raw HTTP, with no browser rendering at all, which is why it can execute in milliseconds.
This approach is high-effort per merchant (you have to reverse-engineer each retailer's specific anti-bot integration and maintain it as the detection systems update) but extremely fast and reliable for the merchants you do support. Because the top 10 merchants covered ~50% of traffic, investing heavily here had outsized impact on the overall automation rate.
Graph neural network. For the broader set of merchants, we developed a machine learning approach. A checkout flow is, at each step, a DOM tree. The system needs to look at the current state of the page and decide: which element do I interact with, and how? Do I click the "Add to Cart" button? Do I fill in the address line 1 field with the customer's street address? Do I select "Medium" from the size dropdown?
We framed this as a graph problem. A DOM tree is a graph. Each node has attributes (tag name, class, id, text content, position, visibility). The model learned to predict which node to interact with and what action to take, given the current state of the page and the context of the transaction (what step of checkout we're on, what information we still need to enter). This was the most research-intensive method — it required building an internal ML data annotation team of 3 managers and 50+ annotators to label training data — but it was also the most generalizable, provided we could pull it off. A request-based bot script for Amazon doesn't help you on Target. A graph neural network trained on enough checkout flows can generalize to merchants it's never seen.
Hardcoded XPaths. For a middle tier of merchants where we had enough volume to justify custom work but not enough to warrant a full request-based bot integration, we used hardcoded XPath selectors. At each step of the checkout flow, the system looks at the DOM, finds the element matching a pre-defined XPath expression, and executes the appropriate action. This is brittle — if the retailer changes their page structure, the XPaths break — but it's fast to build and works well for merchants with stable checkout flows.
Manual execution. The human team. Workers — primarily in the Philippines, later also in Romania — who manually completed purchases using customer credentials. This was the most expensive method per order and had the lowest throughput ceiling (you need more humans to process more orders, and humans have a maximum speed). It was also the fallback for everything: unknown merchants, failed automations, edge cases. The goal was to shrink the proportion of orders routed here as aggressively as possible.
The economics
The business logic was straightforward. Each execution method had a cost per order:
The manual team was the most expensive. A human worker takes minutes per transaction, and you're paying wages, overhead, and operational costs for the call center. Automated methods cost a fraction of that — server costs, proxy fees, CAPTCHA solving services — and execute in seconds.
Revenue came from several sources. The most visible was a $1 fee per transaction charged to users. Second, Nate used Stripe Issuing to generate virtual credit cards for each purchase — because Nate was the card issuer, it earned a share of the interchange fee on every transaction. Third, before executing a purchase, the system would check affiliate networks like Rakuten for an affiliate link to the product — if one existed, Nate would route the purchase through that link and collect affiliate commission on top of the transaction fee.
This revenue model had a structural advantage over competitors like Klarna, which required direct merchant integrations and revenue-sharing agreements with each retailer. Because Nate's automation operated from the consumer side of the checkout — purchasing as if it were a user, not through a merchant API — it didn't need merchant cooperation or revenue splits. This gave it better unit economics per transaction on the merchants it could automate, at the cost of the technical difficulty of actually automating the checkout.
The north star calculation: take the weighted average cost per order across all execution methods (weighted by the proportion of orders each method handles), and compare it to the average revenue per transaction. The end goal was to get average revenue higher than average cost. The way to get there was to shift more and more orders from the expensive manual column to the cheap automated columns.
Every percentage point of automation rate improvement meant real margin improvement. Going from 0% to the high 70s wasn't just a technical milestone — it fundamentally changed the unit economics of every transaction.
What we built
Under my team's work, the automation rate went from 0% to the high 70s percent. This involved building and managing the automation infrastructure: the order routing system, the request-based bot integrations for top merchants, the ML pipeline and annotation team for the graph neural network, the XPath-based automation for mid-tier merchants, and the integrations with anti-bot detection bypass tools. I managed the product side of the work, I hired and managed the data annotation team, and I brought in specialists from the sneaker bot community like Jeffery.
The 70% was real. It was measured internally, and it represented the proportion of orders that completed from end to end without a human touching them. The remaining ~30% still routed to the manual team — either because we had no automation for that merchant, or because an automated attempt failed.
What the CEO told investors
To my knowledge, Albert Saniger allegedly lied to investors about at least two things: how the app was automated, and how much was automated.
The alleged lie about how. The SEC complaint quotes directly from the Series A pitch deck: Nate's "neural networks understand HTML and transact on websites in the same way consumers do" (SEC Complaint, Case 1:25-cv-02937, ¶53). The Seed Round pitch deck described Nate as "a digital assistant able to transact online without human intervention" and "the first non-human executive assistant that can buy anything, anywhere" (¶30). Saniger specifically told investors the app used "neural networks" to process purchases in an average of "only 10 seconds" (¶32). He differentiated Nate from competitors by saying it used AI rather than bots, noting in his own pitch deck that "bots crash every time the merchant adds a new product to the site, does A/B testing, or makes a permanent change to its design or order flow" (¶60). None of this described the system we were actually building. We were not building neural networks that "understand HTML." We were building request-based bots, graph neural networks for DOM interaction, and hardcoded XPath scripts — real automation, but a fundamentally different kind of technology than what Saniger described to investors.
The alleged lie about how much. When an investor asked about the "failure rate today in terms of when a human needs to get involved," Saniger responded on February 28, 2020: "If you look at the automation piece only... success ranges from 93% to 97%... However, by looking at our target audiences and the sites that hold the highest concentration, its above 99% success" (¶37). The SEC states this was false: "as of February 2020, virtually all orders placed by Nate's users were manually completed, including by overseas contract workers" (¶39). As late as June 11, 2021 — the same month the Series A closed — a Nate automation employee confirmed to Saniger in a Slack message that the automation rate was "essentially zero" (¶57).
Saniger restricted access to the internal automation dashboard and told employees the data was a "trade secret." He instructed engineering leads not to report on the status of AI development to other employees (¶22). Most of the company lacked visibility into the real numbers (¶23).
Total investor losses were in the tens of millions. The company dissolved in January 2023 after The Information's June 2022 exposé killed a planned Series B.
He was charged with securities fraud and wire fraud, each carrying up to 20 years. He currently resides in Barcelona. No other employees were charged or named in either the DOJ indictment or the SEC complaint.
The timeline
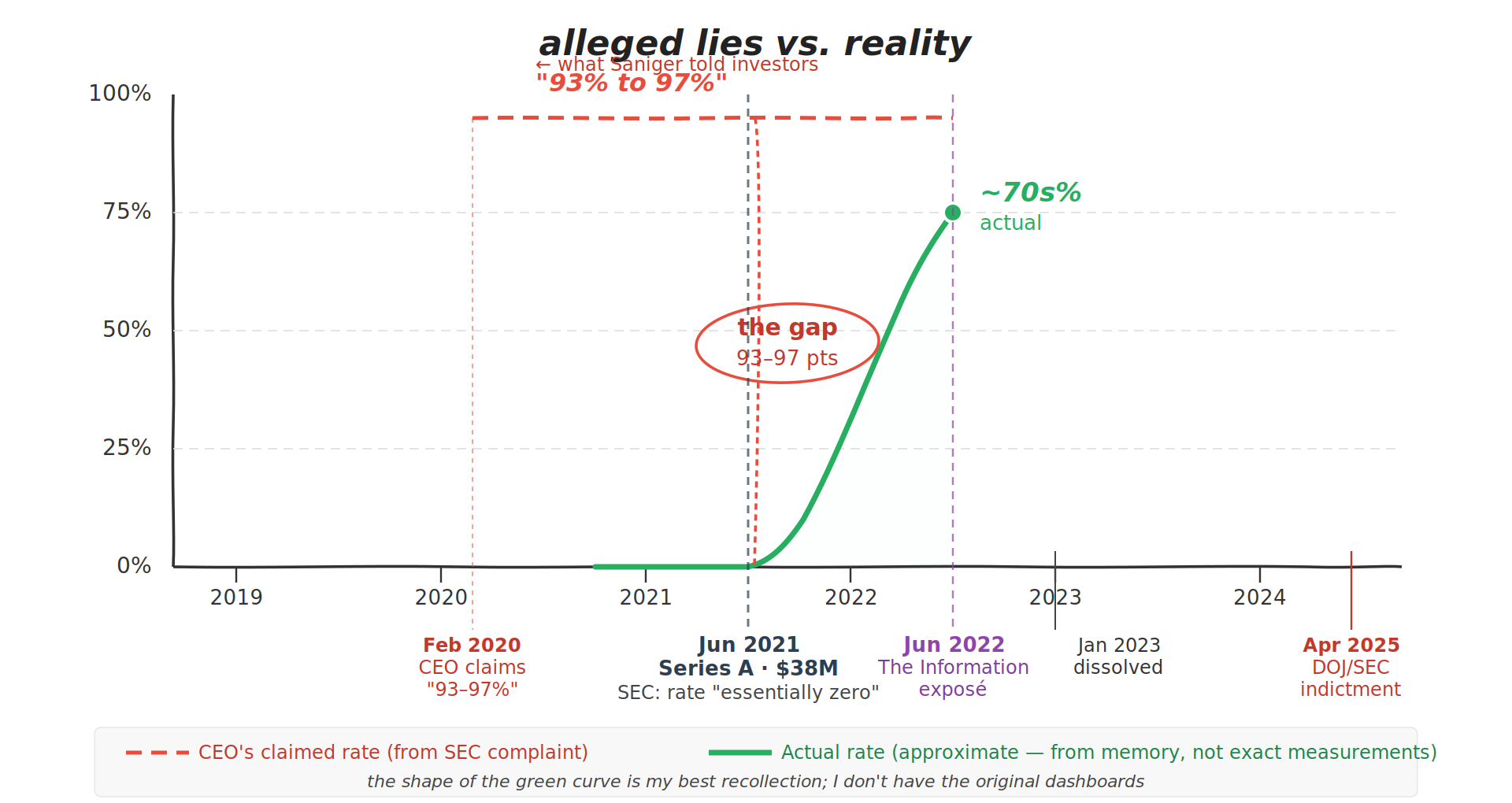
The gap between what the CEO told investors and what the technology actually did narrowed over time — but Saniger never updated his claims to reflect reality. The SEC complaint confirms that as late as June 11, 2021, the automation rate was "essentially zero" (¶57). The automation infrastructure was built after that point, reaching the high 70s by the time I left in mid-2022. The graphic above is approximate — it reflects my recollection of the growth trajectory, not precise measurements. If any of my former colleagues are reading this and have a better recollection of the numbers, please reach out — I'll update the chart.
The gap
I don't care about Saniger making millions. I do care about the lack of integrity — allegedly lying to investors who believed in him, and in doing so making life harder for every other entrepreneur honestly trying to raise for something legitimate.
Like most (all?) of my colleagues, I never saw the pitch deck Saniger was showing investors. Most employees didn't have visibility into the full picture. I was focused on the technical problem — building systems that could actually automate checkout across thousands of retailers — and the numbers I tracked were real measurements of real automation performance.
The distinction matters because the press coverage, and the DOJ press release, describe the technology as essentially nonexistent. But the system we built was real — it processed tens of thousands of transactions. The architecture described above was real, operational, and improving. What was fake was the story the CEO told about it.
Frequently Asked Questions
What was Nate?
Nate (nate.tech) was an e-commerce shopping app founded in 2018 by Albert Saniger. Users could share a product link from any online retailer, and Nate would complete the purchase automatically. The company raised approximately $51 million, including a $38 million Series A in June 2021, before dissolving in January 2023.
What was the Nate fraud?
CEO Albert Saniger told investors that Nate's shopping app was powered by proprietary AI with a 93–97% automation rate. The DOJ and SEC allege the actual automation rate was "effectively zero percent" at the time of those claims, and that hundreds of human workers in the Philippines manually completed purchases. Saniger was charged with securities fraud and wire fraud in April 2025.
Who was charged in the Nate fraud?
Only CEO Albert Saniger was charged. The DOJ filed criminal charges (securities fraud and wire fraud, each carrying up to 20 years), and the SEC filed a parallel civil complaint. No other Nate employees were charged, named as defendants, or identified in either filing. Saniger pleaded not guilty in December 2025.
Was Andrew Agathon involved in the Nate fraud?
No. Andrew Agathon (formerly Andrew Brozek) was the Director of Product (Automation) at Nate from 2020 to 2022. He worked on the team that built the automation infrastructure, increasing Nate's actual automation rate from 0% to the high 70s percent. He was not charged and not named in any DOJ or SEC filing. The fraud charges relate solely to CEO Albert Saniger's misrepresentations to investors about the automation rate and the nature of the technology.
What did Andrew Agathon do at Nate?
Andrew led the product side of the automation team at Nate, alongside peers leading engineering and data science. The team developed Nate's order execution architecture, which included four automation methods: request-based bots (adapted from sneaker bot technology) for top merchants, a graph neural network for generalizable checkout automation, hardcoded XPath-based scripts for mid-tier merchants, and a manual execution team as fallback. Andrew created and managed the ML data annotation pipeline (3 managers, 50+ annotators), brought in specialists from the sneaker bot community, and drove the product strategy that shaped how the automation methods were prioritized and deployed. Under the team's work, the real automation rate grew from 0% to the high 70s percent.
What is the sneaker bot connection to Nate?
Nate hired engineers from the sneaker bot community, including Iwan Jeffery, creator of Splashforce — one of the most prominent sneaker bots on the market. Sneaker bots solve the same technical problem Nate faced: programmatically completing purchases on retailer websites that use anti-bot protections. The key technique is request-based: rather than opening a browser, the bot sends raw HTTP requests directly to retailer endpoints and submits fabricated "sensor data" payloads that anti-bot systems (Akamai, PerimeterX, Cloudflare) accept as coming from a real human. This requires reverse-engineering the anti-bot system's obfuscated JavaScript to understand what data it collects and how it encrypts the payload. These skills were directly applied to building Nate's automated purchasing system for top merchants.
Who is Iwan Jeffery?
Iwan Jeffery is the creator and CEO of Splashforce (Force Software), a commercial sneaker bot. Jeffery is a self-taught British developer who built Splashforce from a Python script into a product generating $700,000 in annual sales by age 21. Business Insider profiled him in September 2020. He was hired at Nate to apply his expertise in request-based automation and anti-bot detection bypass to the company's checkout automation system.
What is the difference between what the DOJ says and what actually happened?
The SEC complaint states that the automation rate was "essentially zero" as confirmed by a Nate automation employee in a Slack message to Saniger on June 11, 2021 (¶57). This was accurate at the time of the Series A. The automation infrastructure was subsequently built by the engineering team, raising the actual rate to the high 70s percent by mid-2022. Saniger allegedly lied about two things: how the app was automated (claiming "neural networks" when the real system used request-based bots, graph neural networks, and XPath scripts) and how much was automated (claiming 93–97% when the real rate was near zero at the time).
Sources
- SEC Complaint — Securities and Exchange Commission v. Alberto Saniger Mantinan, Case 1:25-cv-02937, S.D.N.Y., filed April 9, 2025.
- DOJ Indictment — United States v. Albert Saniger, S.D.N.Y., unsealed April 9, 2025.
- DOJ Press Release — "Tech CEO Charged in Artificial Intelligence Investment Fraud Scheme," U.S. Attorney's Office, Southern District of New York, April 9, 2025.
- Business Insider — "How a self-taught developer with no formal training made $700,000 in sales this year from his sneaker bot, Splashforce, that nabs hyped pairs in just milliseconds," September 2020.
- The Information — "Shaky Tech and Cash-Burning Giveaways: 'AI' Shopping Startup Shows Excesses of Funding Boom," June 13, 2022.